
The terminology around AI and ML is very muddled.
Artificial intelligence is a broad term that refers to a problem that we want to solve, namely how can we get computers to behave more intelligently. It doesn’t prescribe any technique so artificial intelligence can refer just to vanilla old-school search algorithms used to play chess as well as optimiziation techniques used for routing in ride-sharing apps as well as deep learning techniques used to play League of Legends. It basically just covers everything.
Machine learning refers to a system where you push data to a mathematical model until it does what you want:

[Training_Data] + [Model] = [Trained_Model]
This way, you achieve intelligence without explicity programming the intelligence. You create the blank slate and then choose the best training data to show the blank slate so that it picks up some representation of what you want.
You’re trying to learn some function f(A) = B
There are 3 kinds of machine learning problems:
1) Supervised — you know the right answer i.e. you know both A and B for your training data
An example of this would be classifying pictures by label (dog, cat, hot dog, person, etc.)
2) Unsupervised — you don’t know B, you only know A for your training data
This is generally used for data exploration and not something we will focus on.
An example of this would be clustering customers by preference
3) Reinforcement — you don’t know B, but you have some kind of reward/punishment signal
This is generally used when you have some independent outside system you want to model
An example of this would be learning an AI for a board game
After every move, you get back a signal for how well you did based on the board state.
We’re going to be predominantly focused on supervised problems as these are low hanging fruit in the ML world.
How does ML work?
Let’s focus in on a supervised machine learning problem: simple linear regression. We have a bunch of points and we want to learn a line that approximates those points so that we can predict new points.
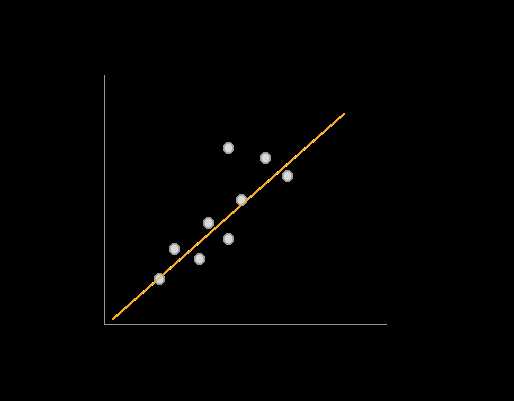
For example, this could be apartment square footage and rental price.
The dots are our training data.
The line is our mathematical model. It is a function f(x) = ax + b with two parameters that we can tune. Our intercept b:

And our slope a:

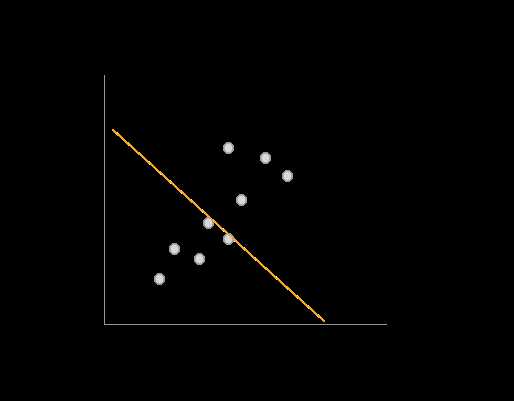
Imagine you have two knobs, one to control a and one to control b. You can fiddle around with these and produce many different lines. Some will be relatively “good” lines:

Some will be relatively “bad.”
The way we determine mathematically whether it is good or bad is with a loss function. Let’s say we chose a = 1.1 and b = 0.1. A loss function takes our current model f(x) = 0.1 + 1.1x and evaluates it against our training data. There are many types of loss functions you can choose from. For linear regression we generally use mean squared error, where we take the distance between the actual f(x) from the training data and the predicted f(x) from our model and square it. (we do this for each point.)
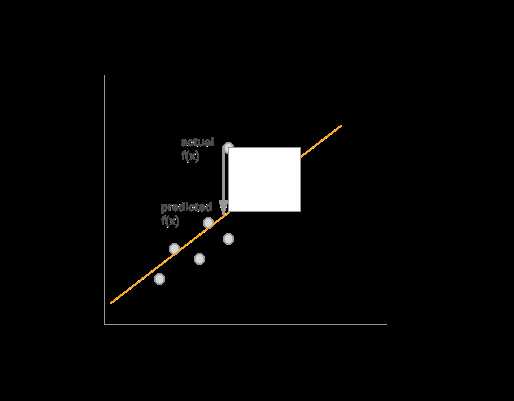
So to find the best line, we just need to tweak a and b to get the lowest loss possible. There are various algorithms for doing this, which we won’t get into now.
This is all about ML AI as of now, stay tuned for more content like this.












